In Wildfly transaction can span many instances of application servers. When transaction is propagated from one AS to another then server from which transaction originates enlists the target AS as one of its subordinate XAResources and it uses standard XA two-phase protocol to perform commit/abort operations. Transaction can span many ASs in arbitrary topology. In this article we will, based on an example, describe in detail how transactions are propagated, how they are recovered in case of failure and what are the responsibilities of administrator.
Propagation example
On pictures below we see example which we will use to describe internals of transaction propagation. This example consist of two application servers (denoted further as AS) and two database servers. On picture 1 one can see flow of transaction before commit. Orange squares indicate branches of transaction executing on a given node.
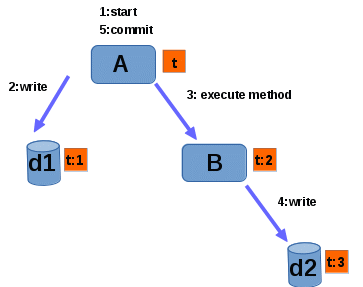
We will describe in more detail individual steps to see what's happening behind the curtain:
1. A starts the transaction. Transaction receives an identifier t.
2. A writes data to database d1. As a result of this d1 is enlisted as XAResource in t. Transaction is identified in XAResource by it's xid which is XA compliant transaction identifier. XA transaction can have many branches which are part of one global transaction. Because of that xids consist of two parts. Global transaction id and branch id. We will denote xids in the form g:b where g is global transaction id and b is branch id. Each time a XAResource is enlisted in transaction new branch of this transaction is created. This branch represents part of transaction executing in given XAResource. It is possible that many branches of the same transaction are executing in the same XAResource. We will see such case in the following part of this article. In this example after d1 is enlisted in t then branch t:1 of transaction t is created in d1.
3. A executes method of bean located in B. As a result of that B is enlisted in t as another XAResource and branch t:2 which denotes this transaction in B is created. When B receives method invocation it learns that this invocation is part of a transaction. Because of that B makes transaction t:2 a subordinate transaction. It means that during two phase commit this transaction will be coordinated by another transaction - in our example coordinator is t. We will see how it is done in detail below.
4. B writes data to database d2. As a result of that d2 is enlisted as XAResource in t:2. Branch t:3, that will denote the transaction t in d2 is created. Please note that B is both subordinate to A and a coordinator to d2.
5. A commits the transaction.
After A decided to commit the transaction the two-phase commit starts. It begins with the prepare phase. Resource is prepared to commit the transaction if it can guarantee that it is able to commit or abort the transaction even in case of node failure. Put it another way, prepared resource must have written log entries which enable transaction commit or rollback to permanent store. Coordinator is responsible for making sure that all of it's subordinates are prepared. Each of resources has a right to abort the transaction in prepare phase. If at least one resource return abort message the transaction has to be rolled back. As we noted above in hierarchical transaction propagation architecture some nodes can be both coordinator and subordinate. Such node can declare itself prepared to it's coordinator if all of its subordinates are prepared. On picture 2 we can see how sucessfull prepare would like in our example:
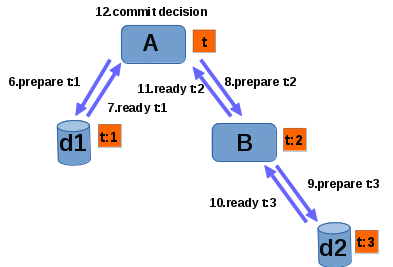
6. A sends PREPARE t:1 message to d1.
7. d1 responds with READY t:1.
8. A sends PREPARE t:2 message to B.
9. B sends PREPARE t:3 message to d2: Before B could reply with READY it must make sure that all of it's subordinate branches are prepared.
10. d2 replies with READY t:3.
11. B sends READY t:2 to A: B now knows that all of it's subordinates are prepared, so a result of that it can also mark itself as a prepared XAResource to A.
12. A makes the the decision to commit the transaction.
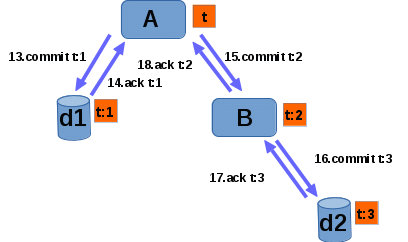
Based on the outcome of prepare phase coordinator on node which created the transaction can decide what to do with it. If all subordinates were able to prepare transaction correctly then transaction can be committed. Otherwise it must be rolled back. Coordinator must wait till all of it's subordinates have acknowledge that they have finished processing the transaction. Again, coordinators which are subordinate to other node can acknowlegde that they finished processing the transaction only if all of their subordinate nodes have finished processing it. Note also that after transaction is prepared and commit/rollback decision is being made then this transaction can be executed correctly even in case of failure of one/many of the nodes. We will look in the following part of this article how failure recovery works. On picture 3 we can see commit phase of successfully executed transaction:
13. A sends COMMIT t:1 message to d1. A as a main transaction coordinator it learns that all of it's subordinates are ready to commit.
14. d1 replies with ACK t:1: This informs A that branch t:1 has committed successfully. A must keep information of the transaction till all of it's subordinates have commited it. More about it in recovery section.
15. A sends COMMIT t:2 message to B.
16. B sends COMMIT t:3 message to d2: As with PREPARE B will be able to acknowledge correct COMMIT completion only after it receives ACK message from all it's subordinates.
17. d2 sends ACK t:3 to B.
18. B sends ACK t:2 to A.
19. A learns that transaction has finished successfully.
What will happen if some of resources is unable to commit? The scenario is very similar. Let's suppose that d2 is unable to commit the transaction. As a result of that in step 10 it sends ABORT message to B. B propagetes ABORT further to A. A learns that one of its subordinates is unable to commit. Because of that it sends ROLLBACK message to all of them. The ROLLBACK message is propagated in the same way as COMMIT.
What happens when something goes wrong?
Node failure during prepare stage
Lets suppose that after data has been written to d2 the node on which it runs fails. Because of that B is unable to sent PREPARE message to d2. After timeout B decides that it is unable to prepare the transaction and it returns ABORT. As a result of that ROLLBACK is propagated to all nodes. And what happens with d2 node? When node recovers it has to restore all the data to consistent state. If there are some changes done to d2 by transaction t then they all have to be reverted. d2 knows about it because it can not have record in its log which indicates that transaction has been prepared. If transaction has not been prepared the node has right to revert it. As a result of that in this scenario d2 knows what to do with t immediately after it is recovered. Please note also that even if the timeout wasn't exceeded before d2 recovers it can also revert the transaction during recovery. If B sends d2 PREPARE message after recovery and before the timeout is exceeded then B can just reply with ABORT message. Generally, we can assume that failures during PREPARE phase will result in aborting of transaction.
Failure of subordinate failure after prepare stage
Lets suppose that after all nodes are prepared node B fails. B managed to send READY to A before failure so A decides to commit the transaction. A sends the COMMIT message to d1 but it is unable to send COMMIT message to node B. When node B recovers it has to restore database to consistent state. It can read from its log that transaction t is in prepared state. B cannot make any decision in this situation because it does not know what decision A made. In order to recover B must wait for action from A. A has written in its log that it has committed the transaction t but it must collect ACK from all it's subordinate resources. A periodically checks if it has some pending transactions that require recovery. In our example A knows that before it can finish processing t I must obtain ACK for all branches that it created. In our example A is able to check that it hasn't committed branch of transaction identified by xid t:3. Because of that periodically checks if node on which t:3 was running has already been recovered. When node B is recovered A finds out about it and it sends COMMIT message to it. When obtains this message it commits t and returns ACK.
Failure of coordinator after prepare stage, heuristic outcomes
Lets suppose that A fails after it decides to commit the transaction. When it recovers again it will read from it's log that it should send COMMIT to d1 and B. It will do it and transaction will be completed. Please note however that before A is recovered then d1 and d2 must be blocked. Because B, d1 and d2 doesn't know what the result of commit is they have to keep their branches of t in prepared state. That means that all locks aquired by t in d1 and d2 cannot be released till A recovers, if those nodes want to be sure that the transaction is executed correctly. It is not always the case that node can wait indefinitely for a coordinator to recover. That's why some nodes can wait for some specified amount of time and if this time is exceeded they can decided themselves what to do with a transaction. In such situation there is no guarantee that transaction will be processed correctly. Such case is called heuristic outcomes of a transaction. In case of heuristic outcomes occurrence it is a responsibility of administrator to check that all nodes that finished the transaction heuristically are in consistent state.
Responisibities of an administrator
Recovery infrastructure is able to perform recovery in all cases except heuristic outcomes. Administrator is responsible for amending failed nodes and checking if any heuristic transaction completion took place. If there are many nodes which failed they can be restored in any order. Connections to other servers that might have took part in transactions that require recovery are created based on remoting subsystem outbound-connections configuration. Because of that any configured outbound-connections that were available during failed transaction execution must be present after recovery. In case some XAResource has completed the transaction heuristcally then administrator must check manually whether commit/rollback decision was consistent with transaction outcome and in case of inconsistencies repair it manually.
Cyclic transaction invocation, branch merging
Lets suppose that after step 4. B invokes a method of a bean deployed in A and then A again writes data to d1. As a result transaction is propagated back from B to A. Another branch t:4 is created. This branch is executed on A. We can see that in such situation there are two branches of t executing on A. Branch t:4 is subordinate of t:3 and it is commited according to two phase protocol. On picture 5 we can see how successfull commit invocation would look like in such scenario.
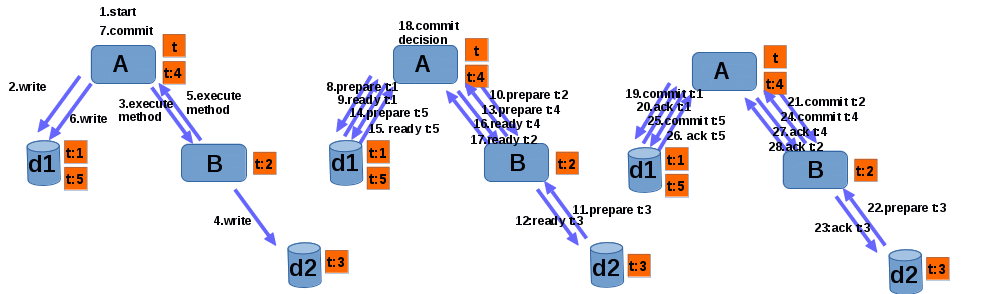
We can see that although t and t:4 are part of the same transaction they are prepared independent of eachother. t:4 is prepared and committed as if it was executing on a node without any previous transaction branch. Note however, that transactions can be merged by some XAResource if necessary. In our example database d1 also has two transaction branches executing. If database engine enables that, this two branches can be merged so that they are seen as part of one transaction and they don't block eachother.